What is the NVIDIA Cosmos Tokenizer and how is it better than traditional tokenization?
Discover NVIDIA's Cosmos Tokenizer—a breakthrough in data processing for AI. Explore its architecture, features, and impact on scalable neural networks.




In the rapidly advancing world of generative AI, tokenizers play a crucial role in transforming raw data into efficient, compressed representations. These components discover latent spaces through unsupervised learning, enabling AI models to work more efficiently with high-dimensional data. Specifically, visual tokenizers are essential for converting images and videos into compact semantic tokens, allowing models to train at scale while minimizing computational resources.
NVIDIA's latest breakthrough in this domain is the Cosmos Tokenizer, a comprehensive suite of continuous and discrete visual tokenizers optimized for both images and videos. This new suite promises superior performance in terms of compression, reconstruction quality, and speed, achieving up to 12x faster processing than existing methods. Let's dive deep into the architecture, functionality, and performance of Cosmos Tokenizer to understand why it stands out in the field.
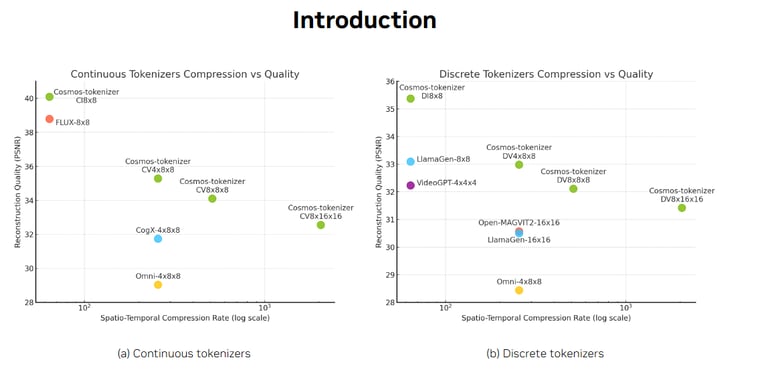
Cosmos Tokenizer
The Cosmos Tokenizer suite includes both continuous and discrete tokenizers for high-resolution images and videos. It supports flexible compression rates and is optimized for diverse visual data types, such as images with different aspect ratios and long-duration videos. Key highlights include:
Joint Support for Images and Videos: A unified architecture that tokenizes both images and videos within a shared latent space.
Temporally Causal Design: Ensures that video frames are processed in a causal sequence, maintaining the order of frames.
High Speed and Efficiency: Capable of tokenizing videos up to 12x faster than previous models, handling resolutions up to 1080p on NVIDIA A100 GPUs.
Flexible Compression: Supports spatial compression rates of 8x, 16x and temporal compression rates of 4x, 8x, providing a wide range of configurations for different use cases.
Tokenization: Continuous vs. Discrete
What Are Tokenizers?
Tokenizers are algorithms that convert raw visual data into compact tokens, representing the data in a lower-dimensional latent space. These tokens enable generative models to efficiently learn and reproduce complex patterns in visual data. There are two primary types of tokenizers:
Continuous Tokenizers: These convert visual data into continuous embeddings, often used in models like Stable Diffusion. They map data to a continuous latent space, making them ideal for models that operate on continuous distributions.
Discrete Tokenizers: These convert visual data into quantized indices, commonly used in models like VideoPoet and GPT-based architectures. They are suited for applications that rely on cross-entropy loss, as they map data to discrete latent spaces.

Video Tokenization Pipeline
The Cosmos Tokenizer utilizes a sophisticated pipeline for video tokenization.
Input Video: The video is split into frames.
Encoder: Each frame is encoded into tokens, reducing the data size significantly.
Decoder: The tokens are used to reconstruct the original video, maintaining high visual fidelity.
The Cosmos Tokenizer is built on a temporally causal encoder-decoder architecture designed to process images and videos efficiently. Let's explore its key components:
Encoder
Wavelet Transform: The Cosmos Tokenizer begins with a 2-level wavelet transform that downscales inputs by a factor of four. This transform emphasizes semantic content, allowing for more efficient tokenization.
Residual Blocks and Downsampling: The encoder consists of multiple residual blocks interleaved with downsampling layers. Each block uses:
2D Convolution: Captures spatial features.
1D Temporal Convolution: Captures motion dynamics across frames.
Causal Padding: Ensures that only current and past frames are processed, preserving the temporal causality required for applications like robotics and autonomous driving.
Decoder
Mirrors the encoder architecture but uses upsampling instead of downsampling to reconstruct the original visual data from tokens.
Spatio-Temporal Attention: Enhances the model’s ability to capture long-range dependencies across space and time, crucial for high-resolution video processing


The Cosmos Tokenizer employs a two-stage training approach:
Stage 1 - Reconstruction Loss:
L1 Loss: Minimizes pixel-wise RGB differences between input and reconstructed outputs.
Perceptual Loss: Based on VGG-19 features to capture higher-level visual details.
Stage 2 - Temporal Consistency:
Optical Flow Loss: Ensures smooth transitions between frames, crucial for video tokenization.
Gram-Matrix Loss: Enhances texture details for images.
Adversarial Loss: Fine-tunes the model for high-fidelity reconstructions, especially at high compression rates.
Evaluation and Benchmarks
NVIDIA evaluated Cosmos Tokenizer on various datasets, including:
Image Datasets: MS-COCO 2017, ImageNet-1K, FFHQ, CelebA-HQ.
Video Datasets: DAVIS, and a newly curated dataset called TokenBench for long-duration, high-resolution videos.
TokenBench includes diverse video categories like robotics, driving, and sports, providing a robust benchmark for video tokenizers.
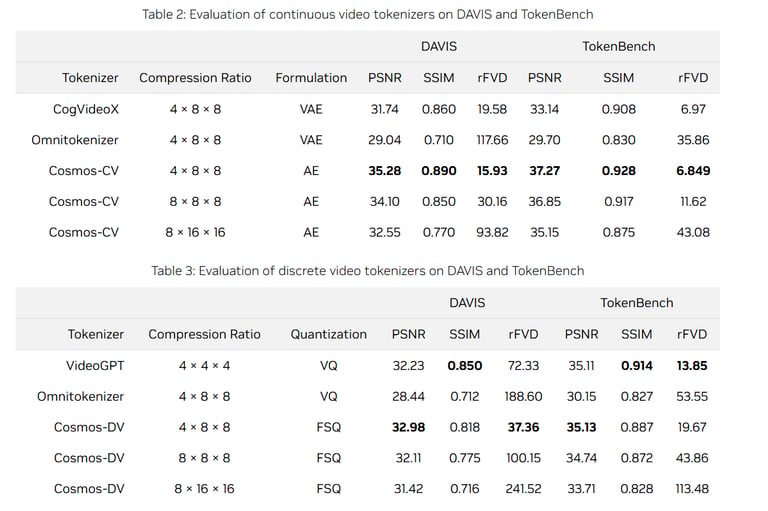
Quantitative Results
The Cosmos Tokenizer outperforms existing methods, achieving:
+4 dB PSNR gain on DAVIS videos.
Significant SSIM improvements, demonstrating better structural similarity.
Up to 12x faster processing speed, enabling real-time applications.
The tables below summarize the performance metrics across continuous and discrete tokenizers


Conclusion
The Cosmos Tokenizer suite by NVIDIA marks a significant advancement in the field of neural tokenization, offering unprecedented speed, flexibility, and quality for both image and video data. Its efficient tokenization process, combined with a robust architecture and advanced training strategy, positions it as a game-changer in generative AI, particularly for high-resolution video applications.
With pretrained models available on GitHub and support for various compression configurations, the Cosmos Tokenizer is set to empower AI researchers and developers in pushing the boundaries of what's possible in visual data processing.
Explore Cosmos Tokenizer
GitHub: NVIDIA Cosmos Tokenizer
NVIDIA Blog: Cosmos Tokenizer Release
Hugging Face: Cosmos Tokenizer Models
Call to Action
Interested in leveraging cutting-edge AI solutions for your business?
Book a call a Below with us at XpandAI to explore how we can help you innovate with AI.