Trusted by Expert Engineering Teams Globally
We move at the speed of thought — shipping elite AI research tools and autonomous agents while legacy firms are still in "planning." Engineering excellence at scale.
Trusted by Expert Engineering Teams Globally
We build deep tools that other agencies barely understand. Our researchers handle the neural math; our coders ship production-ready infrastructure. One day with us is worth weeks with a legacy firm.
Whether you're a founder or enterprise exec — we provide the technical muscle to dominate the AI landscape.
From ideation to a scaling MVP in weeks. We build the core neural architecture and scalable backends that VCs value.
Automate high-latency manual processes. We integrate autonomous agents into your existing tech stack to cut overhead by 80%.
Highly specialized tools for deep research, legal analysis, or medical triage. Custom-built for your specific data set and industry.
Enterprise-grade tools for recursive data extraction, competitor analysis, and market synthesis. We build the research stacks that power decisions.
Agents that reduce 80% of HR workload — handling inbound recruitment, initial screening, and onboarding automation with inhuman precision.
AI-generated video pipelines producing 1000s of minutes of personalized marketing and product content at scale.
Developed an hour-long conversational agent managing complex patient histories and clinical data intake with doctor-level accuracy for high-throughput medical services.
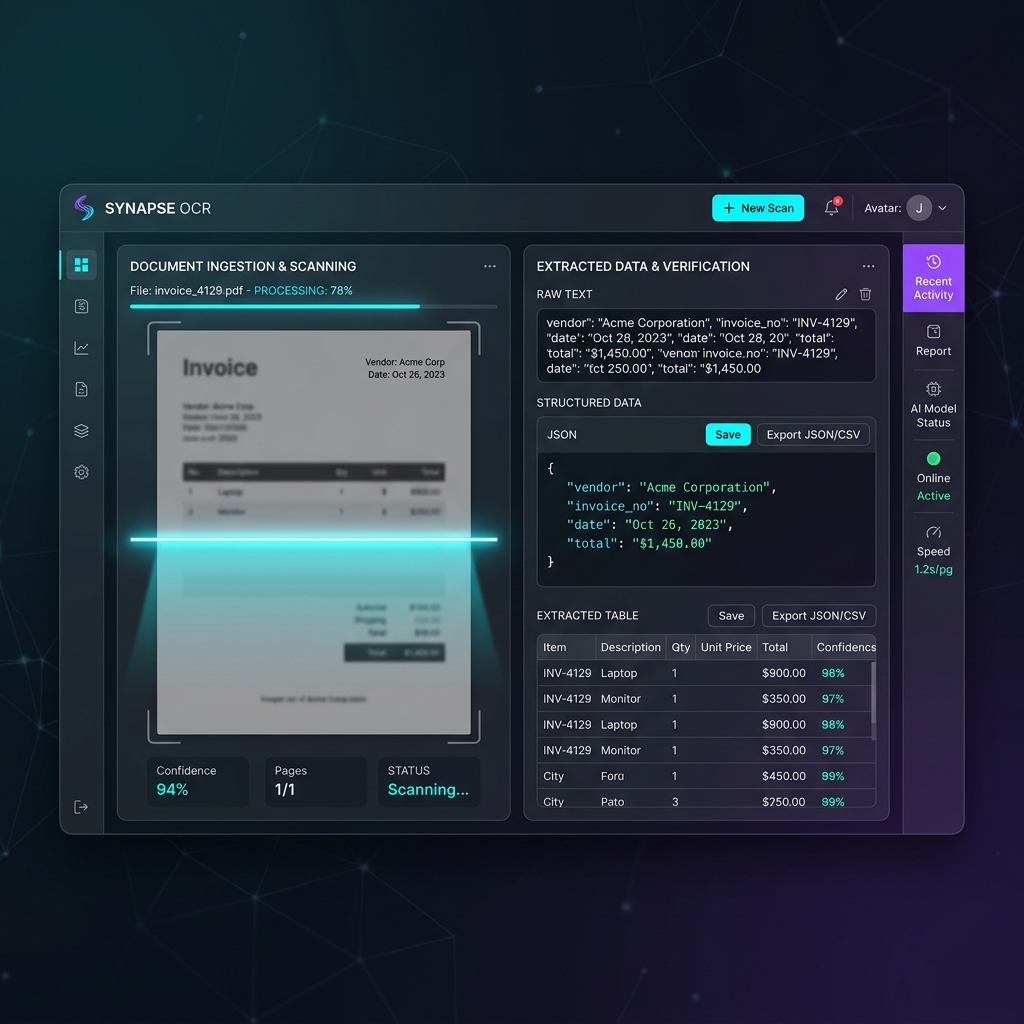
Automated extraction of deep engineering drawing data, transitioning a major logistics project from manual review to a 95% automated flow in record time.
Built an end-to-end recruitment pipeline that screens thousands of applicants, conducts initial technical vetting, and schedules interviews without human intervention.
85% Workload ReductionImplemented recursive research tools for clinical data synthesis and competitor market analysis. Turning months of research into hours of structured insight.
Research at ScaleHuman-level voice synthesis and intent recognition for inbound customer support and outbound logistics coordination.
We build the engine for the future of structured data. From messy handwriting to complex clinical reports, Extract AI handles what other OCR tools ignore.
View Product"XPNDAI's HR Agent reduced our manual screen time by nearly 85%. They're not just coders; they're AI architects."
"The speed of shipment is unmatched. We had our deep research tool live within a week. High authority engineering."
"AutoQME's conversations are indistinguishable from human experts. XPNDAI delivered researcher-level AI quality."
We only build specialized tools. Check your project eligibility to access our expert engineering engagement model.
Project scope verified. Proceed to engineer scheduling.
Book Technical AuditWe're a high-speed AI engineering team. For legacy support, traditional agencies are better suited.

